
はじめに
複数のまちの都市構造の類似性を知りたいとき、どのように類似度を測ることができるでしょうか?一般的には、建物であれば建ぺい率、容積率、土地利用割合、土地利用混合度など、道路であれば道路総延長や交差点密度など、都市構造に関連するさまざまな指標を算出し、それらの指標を総合的に用いて類似性を判定するというアプローチが取られるでしょう。しかし、都市を表す完璧な指標は存在しません。例えば、建物に関する指標では、建ぺい率は建物の形状を考慮できず、土地利用割合も大規模施設が1つある場合と、小規模施設が密集している場合の違いを反映できません。道路に関する指標についても同様で、道路総延長だけでは京都市の中心部のように整然とした道路網なのか、東京都台東区の谷中の「へび道」(谷中名物の路地。かつての川の面影を反映し曲がりくねった形状をしている。)のように複雑な道なのかを区別できませんし、交差点密度もスクランブル交差点のような大規模な交差点と、一般的な交差点の違いを考慮できません。このように、都市を完璧に表す指標が存在しないため、都市の特徴を定量的に評価するには、必要十分な指標を選定し、それぞれに適切な重みを付けるという、非常に困難なアプローチが求められます。一方、近年、複雑な現象の特徴を数値化するツールとしてAIが非常に強力になっています。画像や音声、文章など、一見すると数値化が難しそうなデータに対しても、特徴を数値化し、学習を通じて予測や分類、生成といったタスクを実行しています。このAIの強みは、都市構造の特徴を定量的に把握する上でも有効ではないかと考えました。
そこで本コンテンツでは、できるだけ人の主観を排してAIに都市構造を学習させることで、都市構造の特徴を定量化し、都市の類似性を推定します。その後、推定結果の妥当性を評価し、このAIの活用可能性について考察していきます。
分析手法・分析対象
(1) 学習モデル本分析では、Vision Transformer(ViT) という深層学習モデルとSimSiamという自己教師あり学習の手法を用いて分析を行いました。分析について簡単に説明すると、以下のような手順となります。
① 画像の加工:
もとの画像の一部を切り取る、回転・反転させるなどにより、水増し画像を2つ作成する。
② 画像の数値化:
ViTにより、水増し画像をそれぞれ数値(特徴ベクトル)にする。
③ 学習:
2つの数値化した特徴が近づくように学習させる。
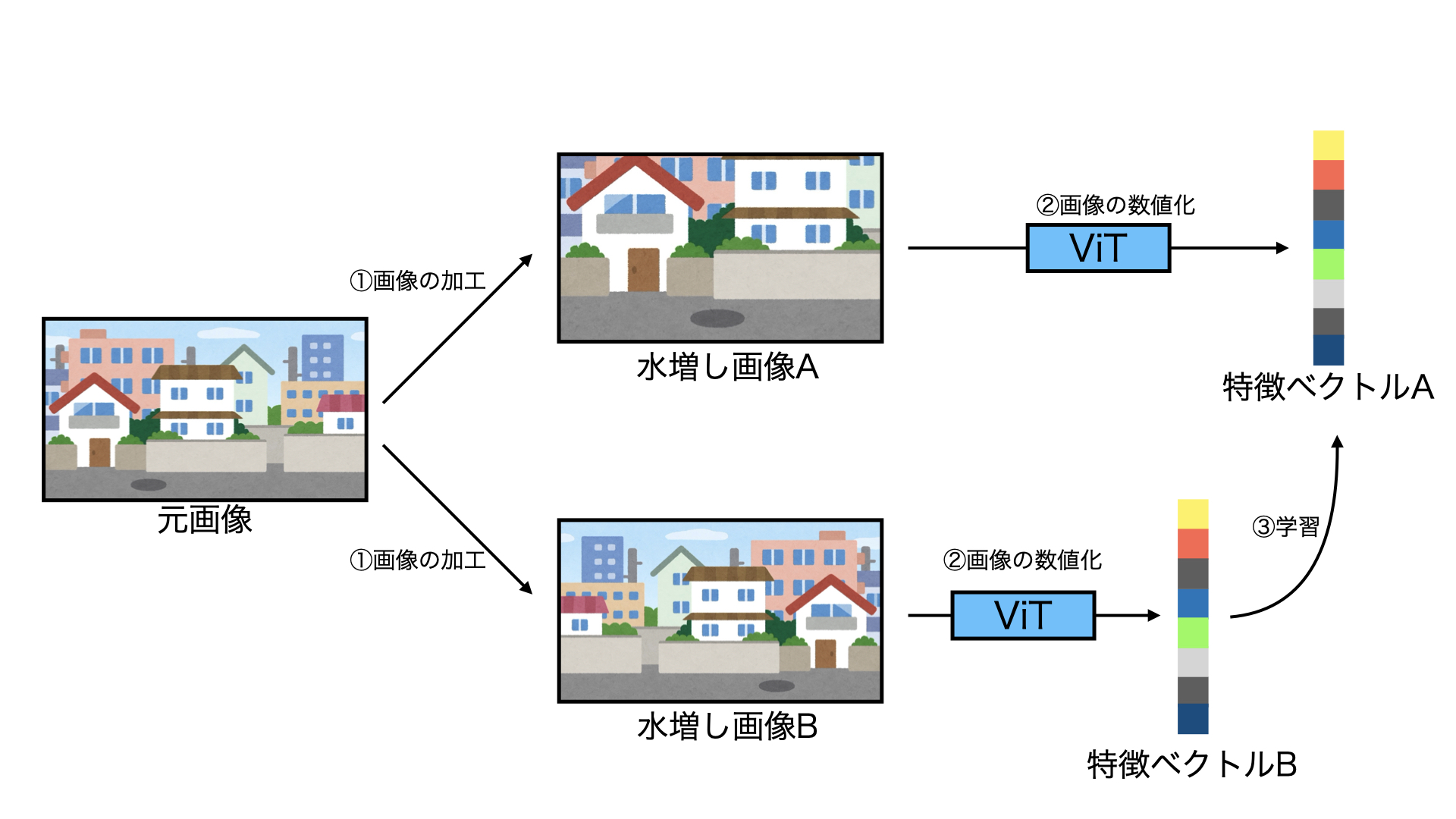
図1: 分析のイメージ
(参考文献[1]をもとに筆者作成)
ViTについてここでは詳細な説明は省略しますが、興味のある方はぜひ補足をご覧ください。
(2) 学習データ
本分析で用いた学習データは、東京23区の建物と道路の地図画像です。国土交通省が提供する都市3Dモデルデータ「PLATEAU」 から建物データと道路データを取得し、加工を行いました。主に行った加工は建物用途の簡易化です。もともとのデータでは建物用途は以下のように細かく分類されていました。
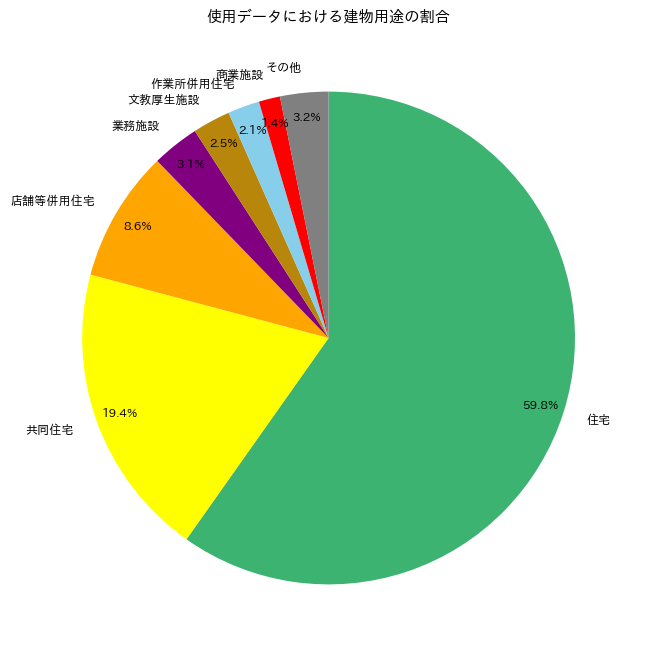
図2: 使用データにおける建物用途の割合
少ないデータセットで都市構造の特徴をAIに学習させる際には、情報を整理し、シンプルな形にすることが重要です。そこで、建物用途を以下の3つに分類しました。
| 学習させた建物用途 | 定義 | 地図における配色 |
|---|---|---|
| 住宅 | 「住宅」と明記されているもの | 緑色 |
| 商業 | 「商業施設」に該当するもの | 赤色 |
| その他 | 上記以外 | 青色 |
都市全体をバランスよく学習させるため、東京都特別区の各区からランダムに500地点を抽出し、それぞれの地点を中心に800m四方の地図画像を作成しました。合計で11,500枚(= 500枚 × 23区)の地図画像を作成し、建物用途ごとに色分けした地図画像をAIの入力データとして使用しました。
下記に、学習に使用した地図データの一部を示します。ただし、建物の形状・規模や用途、建物同士の空間的な位置関係を重点的に学習させることを目的としたため、地図には建物(赤・緑・青)と道路(黒)のみを表示し、公園や河川、線路は空白となっています。
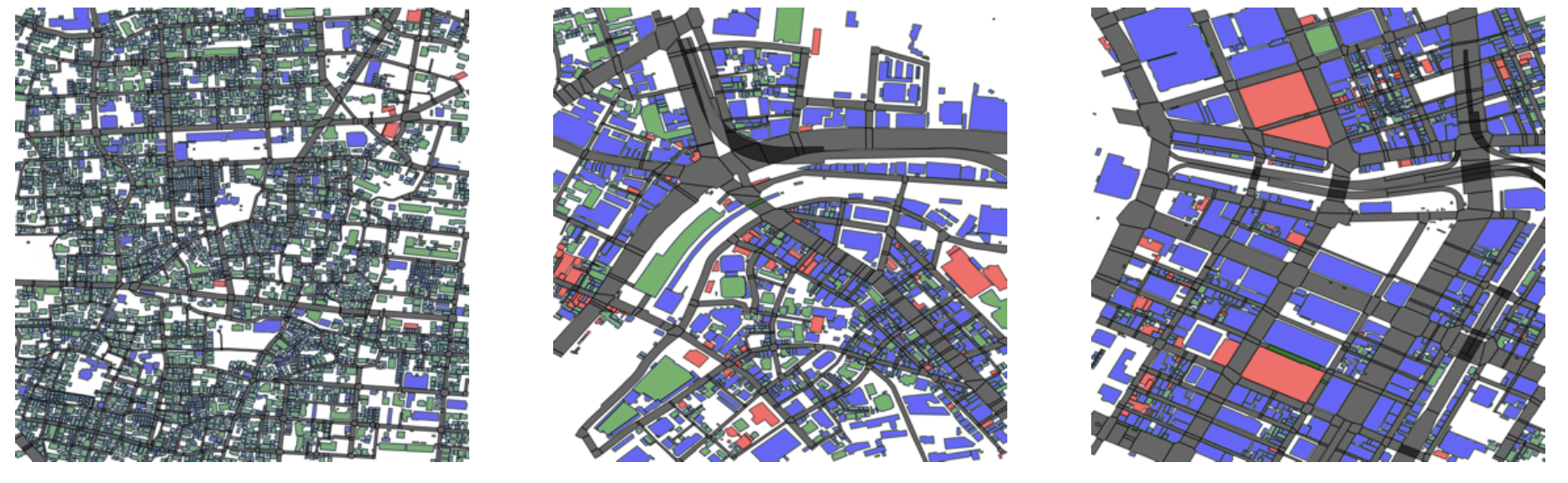
図3: 学習させた都市構造の例
(3)学習の評価
最後に、学習させたAIが適切に都市構造を分類できているかを評価します。ここでは、JR山手線の全30駅について、それぞれの駅を中心に800m四方の地図画像を作成し、AIがこれらの類似度をどのように推定するかを考察することで、特徴抽出の精度を評価します。
本コンテンツでは、類似度の指標として コサイン類似度 を採用しています。コサイン類似度は -1 から 1 の範囲を取り、1 に近いほど類似している、-1 に近いほど類似していないことを表します。
結果
まず、山手線の各駅同士の類似度を算出しました。その結果の概要として、各駅の最も類似している駅と、最も類似していない駅、およびその類似度を表2に示します。| 最も似ている | 最も似ていない | |||
|---|---|---|---|---|
| 駅名 | 類似度 | 駅名 | 類似度 | |
| 東京 | 有楽町 | 0.67 | 駒込 | -0.25 |
| 有楽町 | 東京 | 0.67 | 高田馬場 | -0.23 |
| 新橋 | 目黒 | 0.64 | 新大久保 | -0.12 |
| 浜松町 | 品川 | 0.67 | 高田馬場 | -0.45 |
| 田町 | 上野 | 0.56 | 御徒町 | -0.21 |
| 高輪ゲートウェイ | 品川 | 0.64 | 高田馬場 | -0.37 |
| 品川 | 浜松町 | 0.67 | 高田馬場 | -0.41 |
| 大崎 | 田端 | 0.63 | 御徒町 | -0.32 |
| 五反田 | 渋谷 | 0.7 | 秋葉原 | -0.3 |
| 目黒 | 新橋 | 0.64 | 新大久保 | -0.13 |
| 恵比寿 | 五反田 | 0.62 | 秋葉原 | -0.42 |
| 渋谷 | 五反田 | 0.7 | 秋葉原 | -0.17 |
| 原宿 | 品川 | 0.56 | 高田馬場 | -0.32 |
| 代々木 | 鶯谷 | 0.54 | 高田馬場 | -0.09 |
| 新宿 | 池袋 | 0.61 | 駒込 | -0.05 |
| 新大久保 | 秋葉原 | 0.6 | 大崎 | -0.28 |
| 高田馬場 | 恵比寿 | 0.6 | 浜松町 | -0.45 |
| 目白 | 西日暮里 | 0.43 | 品川 | -0.1 |
| 池袋 | 新宿 | 0.61 | 駒込 | -0.03 |
| 大塚 | 駒込 | 0.62 | 秋葉原 | -0.29 |
| 巣鴨 | 有楽町 | 0.52 | 高田馬場 | -0.11 |
| 駒込 | 大塚 | 0.62 | 浜松町 | -0.39 |
| 田端 | 大崎 | 0.63 | 秋葉原 | -0.25 |
| 西日暮里 | 日暮里 | 0.62 | 秋葉原 | -0.21 |
| 日暮里 | 西日暮里 | 0.62 | 秋葉原 | -0.19 |
| 鶯谷 | 新橋 | 0.55 | 新大久保 | -0.08 |
| 上野 | 新橋 | 0.59 | 新大久保 | -0.12 |
| 御徒町 | 秋葉原 | 0.8 | 恵比寿 | -0.35 |
| 秋葉原 | 御徒町 | 0.8 | 恵比寿 | -0.42 |
| 神田 | 渋谷 | 0.42 | 高輪ゲートウェイ | -0.07 |
最も類似している駅には、隣接する駅同士のペアが多く含まれています(例: 東京と有楽町、日暮里と西日暮里、秋葉原と御徒町)。一方、最も類似していない駅には、秋葉原(7/30)、高田馬場(7/30)、新大久保(4/30)など一部の駅が頻繁に登場しており、特定の駅が他の駅と異なる特徴を持っていることがわかります。
次に、この類似度をもとに、駅のグルーピングを行いました。スペクトラルクラスタリングという手法を用いて、駅を5つのグループに分類し、その結果を表3にまとめました。
| グループ | 駅 |
|---|---|
| グループ1 | 五反田、恵比寿、高田馬場、大塚、駒込 |
| グループ2 | 浜松町、高輪ゲートウェイ、品川、原宿 |
| グループ3 | 目黒、目白、巣鴨、田端、西日暮里、日暮里、鴬谷 |
| グループ4 | 東京、有楽町、新橋、田町、大崎、渋谷、代々木、新宿、池袋、上野、神田 |
以下では各グループに分類された都市構造の具体例を示しつつ、それぞれの特徴を考察していきます。
・グループ1
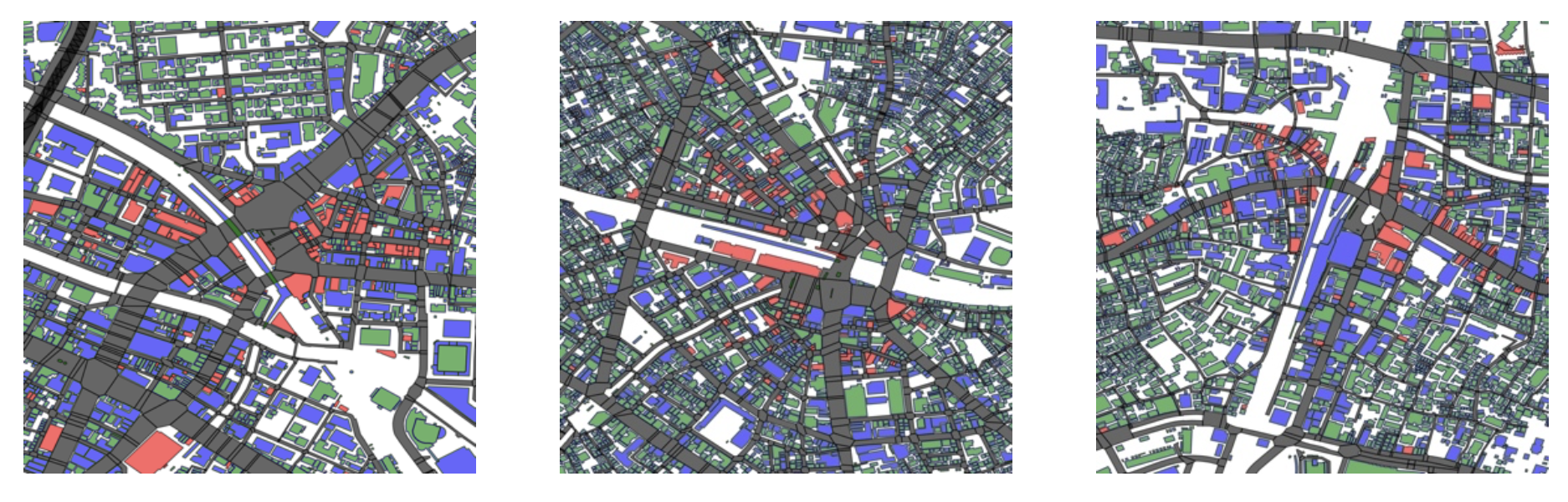
図4: グループ1の都市構造の例
(左: 五反田、中央: 大塚、右: 高田馬場)
画像から、中心に「商業」や「その他」の用途が集まり、その外側に小中規模の住宅を主とした市街地が形成されていることがわかります。このような都市構造が本グループの特徴だと考えられます。
・グループ2
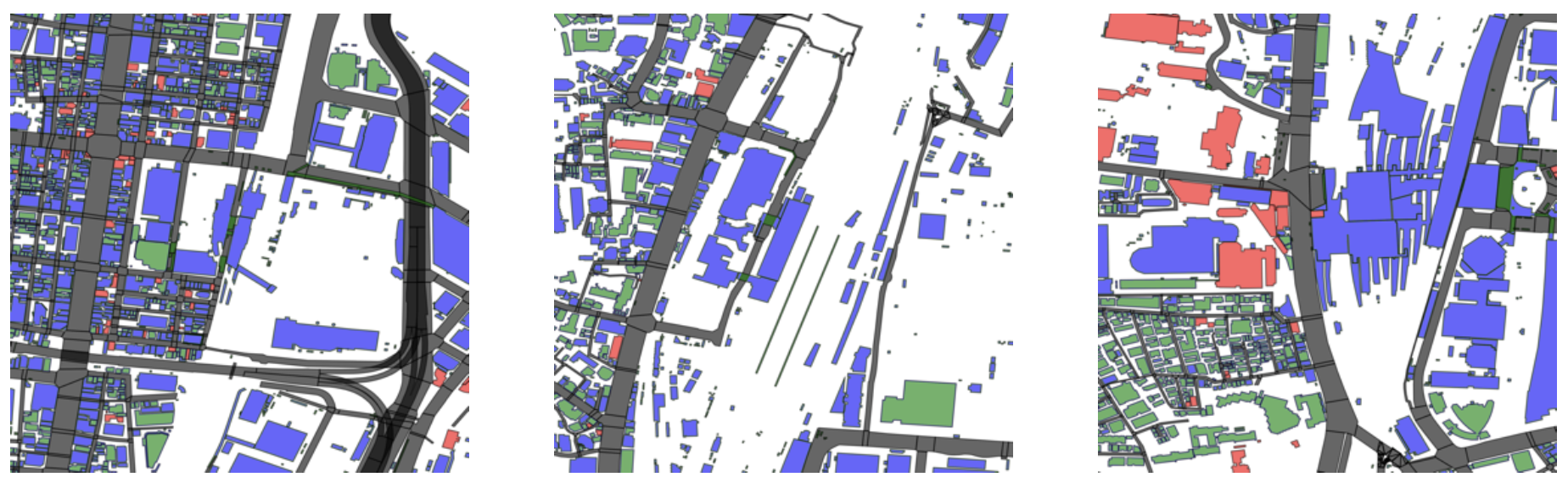
図5: グループ2の都市構造の例
(左: 浜松町、中央: 高輪ゲートウェイ、右: 品川)
本グループでは、建物がない広い空間が目立ちます。これは、線路や大規模な公園・広場(例: 旧芝離宮恩寵庭園(浜松町)、芝浦中央公園(高輪ゲートウェイ)、高輪森の公園(品川))が影響しており、駅前でありながら比較的低密度な土地利用が特徴的です。また、大規模な建物が多く、住宅用途が少ない点も本グループの大きな特徴です。
・グループ3
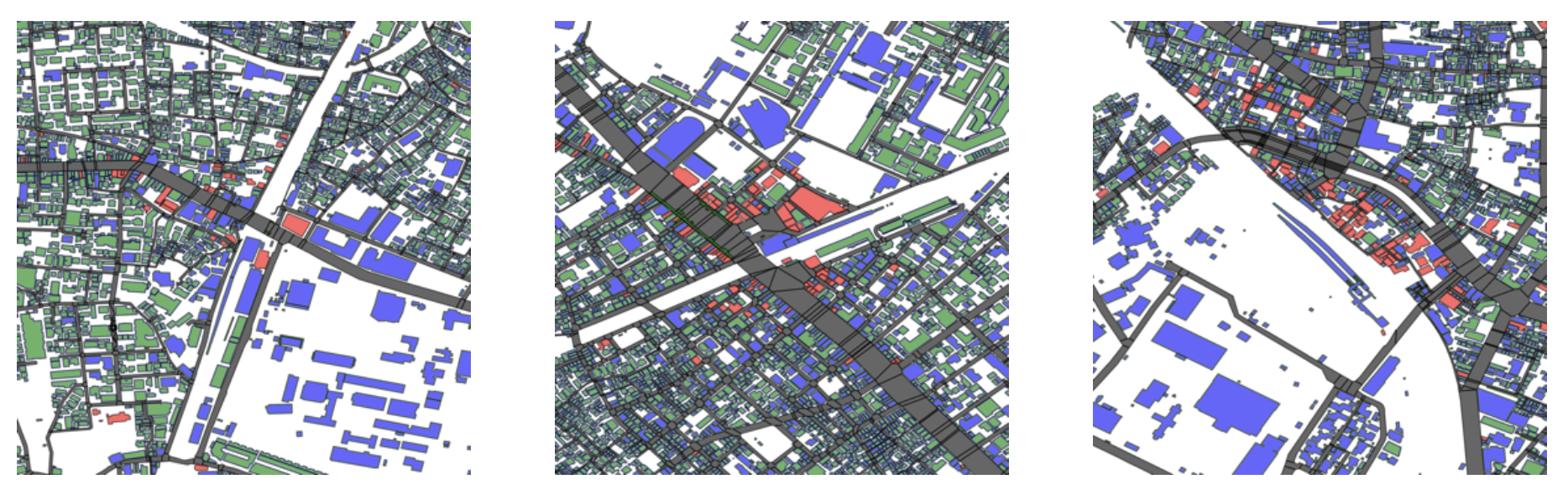
図6: グループ3の都市構造の例
(左: 目白、中央: 巣鴨、右: 鴬谷)
グループ1と同様に、中心に「商業」や「その他」の用途が集まり、その外側に小中規模の住宅を主とした市街地が形成されています。一方、学校やグラウンドなどによる大規模な空地が多い点が、グループ1との違いです。
・グループ4
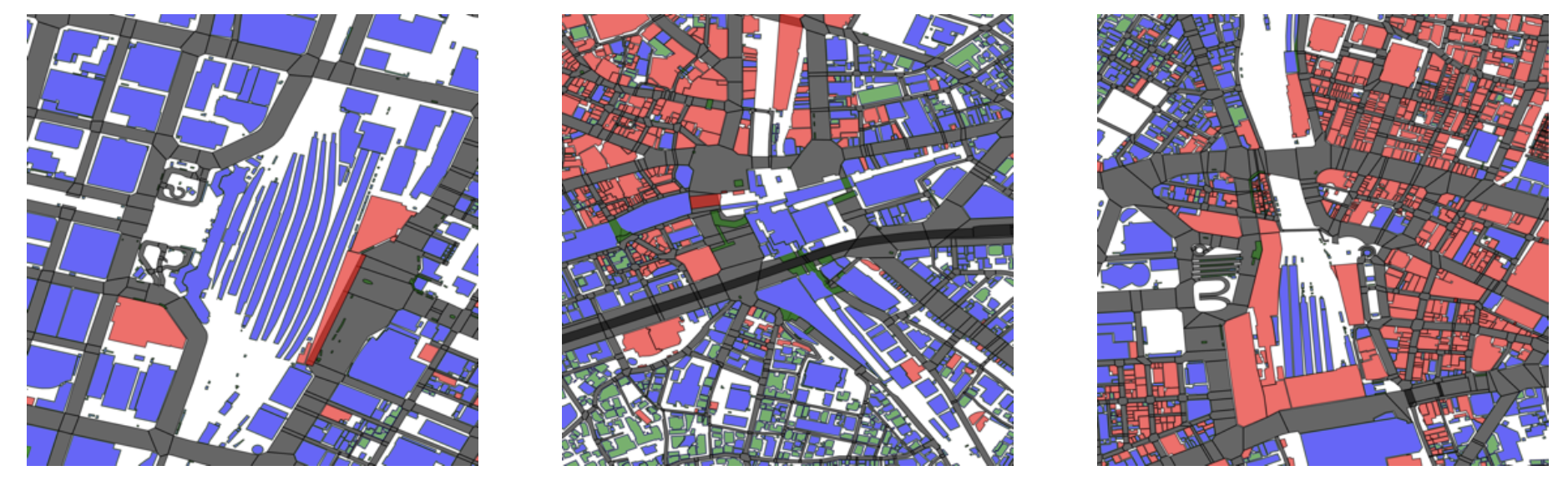
図7: グループ4の都市構造の例
(左: 東京、中央: 渋谷、右: 新宿)
このグループには、東京、渋谷、新宿など、山手線の主要駅が多く含まれています。特徴として、大規模な建物が多く、住宅用途や空地が少ない点が挙げられます。
一方で、神田駅は本来グループ4よりも後述するグループ5の方が適切なのではないかという印象を受けました。この点は、本AIの改善が求められる部分と考えられます。
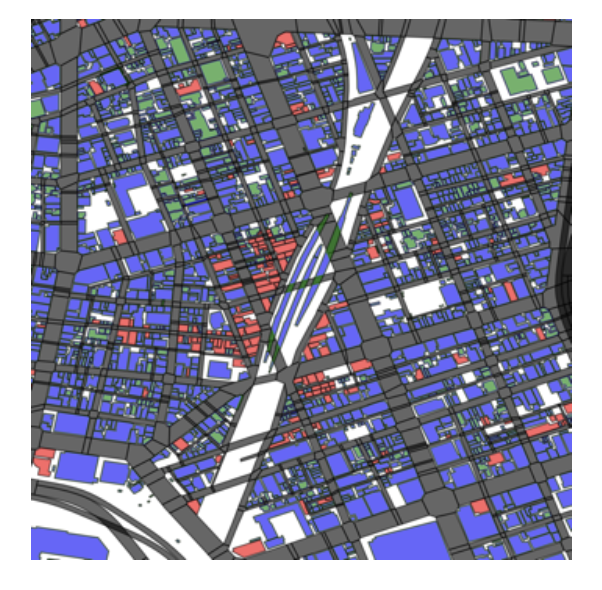
図8: 神田の都市構造
・グループ5
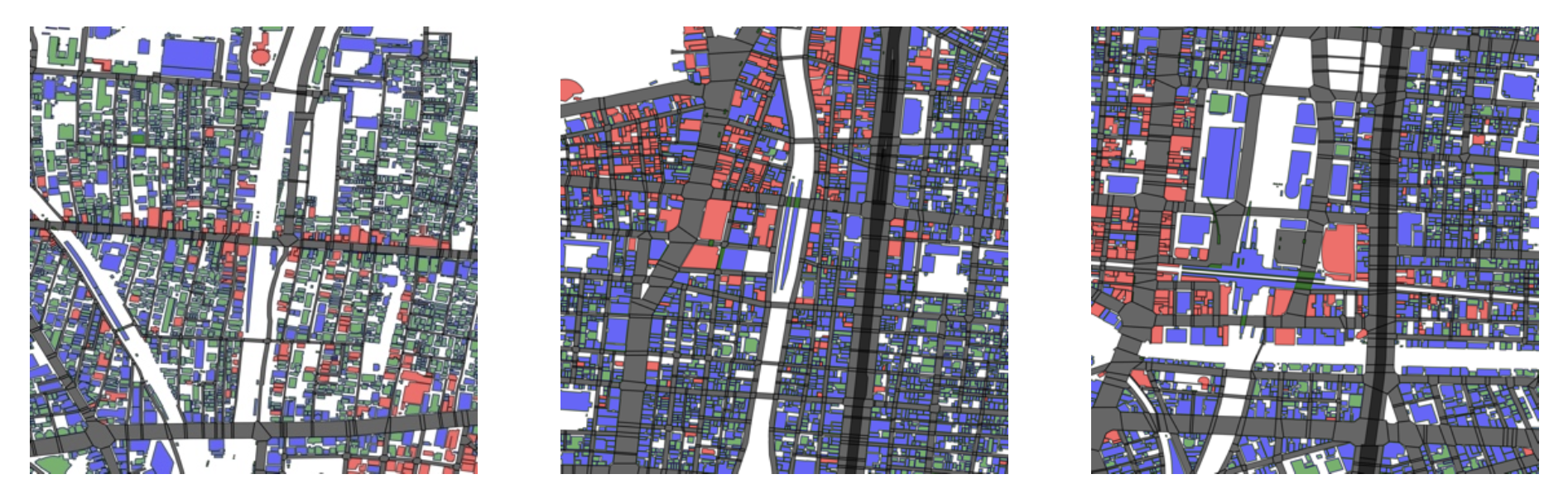
図9: グループ5の都市構造の例
(左: 新大久保、中央: 御徒町、右: 秋葉原)
このグループの都市構造は、小中規模の建物が高密度に密集していることが特徴です。グループ1や3と似ていますが、道路がグリッド状に近く、街区割りが整然としている点が異なります。
おわりに
以上、AIによる都市の類似性推定結果を評価しました。神田のように精度向上の余地がある点も見られましたが、全体的には良好な結果でした。特に、グループ1、3、5については、一括りに「小中規模の建物が密集した市街地」と表現できる都市構造でありながら、空地の有無や道路網を考慮した適切な分類が印象的でした。最後に、都市構造を学習するAIの活用可能性について述べたいと思います。まず、自治体など都市計画を策定する立場では、類似する都市における優れた事例を提示してもらうことで、より良い計画策定の参考にできるでしょう。また、住民の立場では、「勤務地に通勤可能な範囲で〇〇と似たまちに住みたい」といった要望に対して、条件に適したまちをレコメンドしてもらうことも可能です。
本分析では、都市構造を簡易化したデータを学習させましたが、高さなど建物の3次元的な特徴や、より細かな用途分類を考慮した特徴抽出も可能です。今後、AIの活用により、都市計画やまちづくりの分野が大きく発展していくことを期待しています。
補足(Vision Transformer)
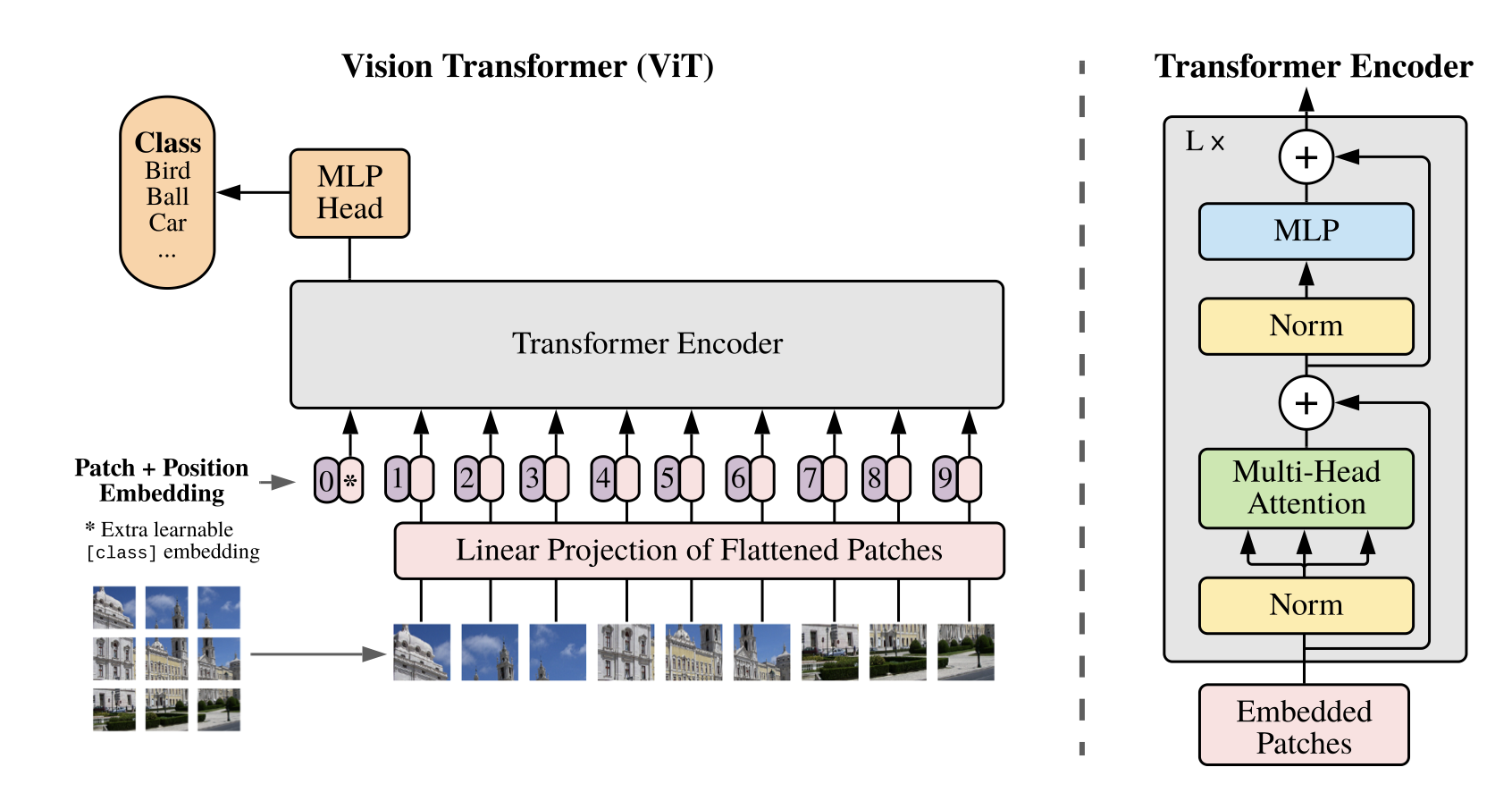
図10: Vision Transformerの構造
(出典: 参考文献[3])
上記が Vision Transformer の構造です。具体的には、まず、画像を小さなパッチに分割し、それぞれを平坦化して特徴ベクトルを算出します。次に、それらを Transformer Encoder に入力します。Transformer Encoder では、アテンション機構を用いることで、画像内の重要な部分を選択的に強調し、計算を行います。これにより、画像の特徴が位置に依存しないという利点があります。例えば、本分析において「小規模住宅の高密度な市街地」が重要だと判定された場合、その市街地が画像の上部にあっても下部にあっても、影響を受けずに特徴を抽出できます。
参考文献
[1] Chen, X., & He, K. (2021). Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 15750-15758).[2] G空間情報センター, 3D都市モデル(Project PLATEAU) ポータルサイト, https://front.geospatial.jp/plateau_portal_site/ (2025/2/28閲覧)
[3] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
[4] 田村雅人, 中村克行. (2023). Pythonで学ぶ画像認識 機械学習実践シリーズ. インプレス.
文責: 山口颯斗